Mise à jour le 12 septembre 2024 par Jacques Tremblay
Si vous voulez fusionner des données de deux fichiers texte en faisant correspondre un champ commun, vous pouvez utiliser la commande JOIN de Linux. Elle ajoute une pincée de dynamisme à vos fichiers de données statiques. Nous allons vous montrer comment l'utiliser.
Correspondre les données entre les fichiers
Les données sont roi. Les sociétés, les entreprises et les ménages sont concernés. Mais, les données stockées dans différents fichiers et rassemblées par différentes personnes sont une source de problème.
En plus de savoir quels fichiers ouvrir pour trouver les informations souhaitées, la disposition et le format des fichiers sont susceptibles d'être différents.
Puis, vous devez gérer des vrais cauchemars administratifs pour savoir quels fichiers vous devez mettre à jour ou sauvegarder, quels fichiers sont hérités ou lesquels sont à archiver.
De plus, si vous devez consolider vos données ou analyser un ensemble de données complet, c’est tout un autre problème. Comment rationalisez-vous les données entre les différents fichiers avant de pouvoir les utiliser ? Comment allez-vous faire une préparation de données ?
La bonne nouvelle est que si les fichiers partagent au moins un élément de données commun, la “command join” de Linux peut vous faciliter la tâche.
Pour voir les applications Linux les plus populaires, consultez notre guide.
Les fichiers de données
Toutes les données que nous allons utiliser pour démontrer l'utilisation de la commande join sont fictives, à commencer par les deux fichiers suivants :
cat file-1.txt
cat file-2.txt
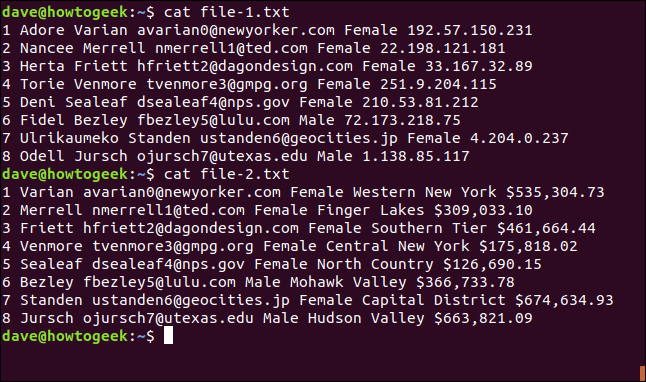
Voici le contenu de file-1.txt :
1 Adore Varian avarian0@newyorker.com Female 192.57.150.231
2 Nancee Merrell nmerrell1@ted.com Female 22.198.121.181
3 Herta Friett hfriett2@dagondesign.com Female 33.167.32.89
4 Torie Venmore tvenmore3@gmpg.org Female 251.9.204.115
5 Deni Sealeaf dsealeaf4@nps.gov Female 210.53.81.212
6 Fidel Bezley fbezley5@lulu.com Male 72.173.218.75
7 Ulrikaumeko Standen ustanden6@geocities.jp Female 4.204.0.237
8 Odell Jursch ojursch7@utexas.edu Male 1.138.85.117
Nous avons un ensemble de lignes numérotées, et chaque ligne contient toutes les informations suivantes :
- Un numéro
- Un prénom
- Un nom de famille
- Une adresse e-mail
- Le sexe de la personne
- Une adresse IP
Voici le contenu du fichier-2.txt :
1 Varian avarian0@newyorker.com Female Western New York $535,304.73
2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10
3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44
4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02
5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15
6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78
7 Standen ustanden6@geocities.jp Female Capital District $674,634.93
8 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09
Chaque ligne du fichier-2.txt contient les informations suivantes :
- Un numéro
- Un nom de famille
- Une adresse e-mail
- Une adresse e-mail
- Le sexe de la personne
- Une région de New York
- Une valeur en dollars
La commande join fonctionne avec des « champs », ce qui signifie, dans cet exemple, une section de texte entourée d'espaces, le début d'une ligne ou la fin d'une ligne.
Pour que join fasse correspondre les lignes entre les deux fichiers, chaque ligne doit contenir un champ commun.
Cela dit, nous ne pouvons faire correspondre un champ que s'il apparaît dans les deux fichiers.
L'adresse IP n'apparaît que dans un seul fichier, donc ce n'est pas bon. Le prénom n'apparaît que dans un seul fichier, nous ne pouvons donc pas l'utiliser non plus. Le nom de famille figure dans les deux fichiers, mais ce serait un mauvais choix, car différentes personnes ont le même nom de famille.
Vous ne pouvez pas non plus lier les données avec les entrées masculines et féminines, car elles sont trop vagues. Les régions de New York et les valeurs en dollars n'apparaissent que dans un seul fichier également.
Cependant, nous pouvons utiliser l'adresse e-mail car elle est présente dans les deux fichiers et chacun est unique à un individu. Un coup d'œil rapide dans les fichiers confirme aussi que les lignes de chaque fichier correspondent à la même personne.
Nous pouvons donc utiliser les numéros de ligne comme champ correspondant (nous allons utiliser un autre champ plus tard).
Notez qu'il y a un nombre différent de champ dans les deux fichiers, ce qui est bien. Nous pouvons indiquer à join quel champ utiliser à partir de chaque fichier.
Cependant, faites attention aux domaines comme les régions de New York. Dans un fichier séparé par des espaces, chaque mot du nom d'une région ressemble à un champ. Bien que certains noms de région contiennent deux ou trois mots, vous avez en fait un nombre différent de champs dans le même fichier. C'est bon tant que vous faites correspondre les champs qui apparaissent dans la ligne avant les régions de New York.
La commande join
Tout d'abord, le champ que vous allez faire correspondre doit être trié. Nous avons des nombres croissants dans les deux fichiers, donc nous répondons à ces critères.
Par défaut, join utilise le premier champ d'un fichier, c'est ce que nous voulons. Une autre valeur sensible par défaut est que join s'attend à ce que les séparateurs de champs soient des espaces. Encore une fois, nous l’avons, donc nous pouvons aller de l'avant et lancer join.
Comme nous utilisons tous les paramètres par défaut, notre commande est simple :
join file-1.txt file-2.txt
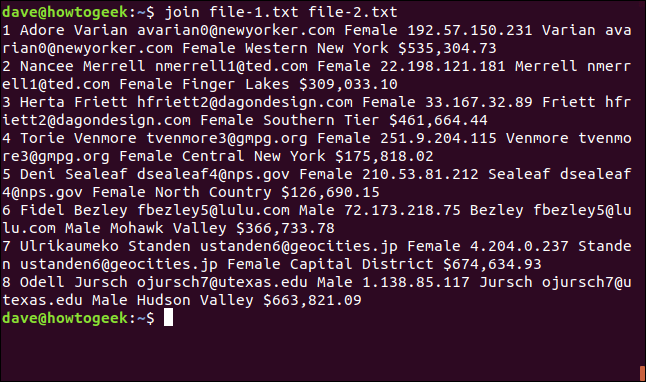
join considère les fichiers comme « fichier un » et « fichier deux » selon l'ordre dans lequel ils sont répertoriés sur la ligne de commande.
La sortie est la suivante :
1 Adore Varian avarian0@newyorker.com Female 192.57.150.231 Varian avarian0@newyorker.com Female Western New York $535,304.73
2 Nancee Merrell nmerrell1@ted.com Female 22.198.121.181 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10
3 Herta Friett hfriett2@dagondesign.com Female 33.167.32.89 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44
4 Torie Venmore tvenmore3@gmpg.org Female 251.9.204.115 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02
5 Deni Sealeaf dsealeaf4@nps.gov Female 210.53.81.212 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15
6 Fidel Bezley fbezley5@lulu.com Male 72.173.218.75 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78
7 Ulrikaumeko Standen ustanden6@geocities.jp Female 4.204.0.237 Standen ustanden6@geocities.jp Female Capital District $674,634.93
8 Odell Jursch ojursch7@utexas.edu Male 1.138.85.117 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09
La sortie est formatée de la manière suivante :
- Le champ sur lequel les lignes ont été mises en correspondance est imprimé en premier,
- Suivi par les autres champs du fichier un,
- Puis les champs du fichier deux sans le champ de correspondance.
Champs non triés
Essayons quelque chose que nous savons déjà qu’elle ne fonctionnera pas. Nous allons mettre les lignes d'un fichier dans le désordre afin que join ne puisse pas traiter le fichier correctement.
Le contenu de fichier-3.txt est le même que fichier-2.txt, mais la ligne huit se situe entre les lignes cinq et six.
Voici le contenu du fichier-3.txt :
1 Varian avarian0@newyorker.com Female Western New York $535,304.73
2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10
3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44
4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02
5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15
8 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09
6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78
7 Standen ustanden6@geocities.jp Female Capital District $674,634.93
Nous tapons la commande suivante pour essayer de joindre file-3.txt à file-1.txt :
join file-1.txt file-3.txt
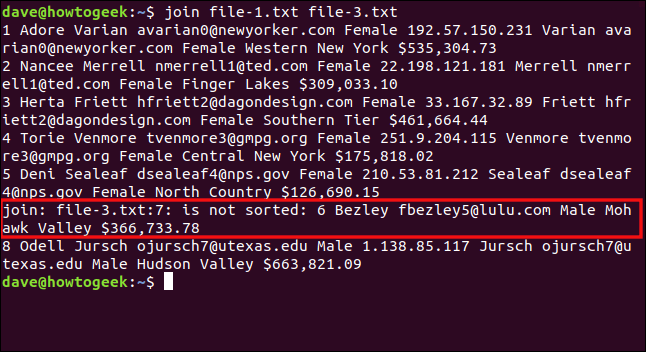
join signale que la septième ligne du fichier-3.txt est en désordre, donc elle n'est pas traitée. La ligne sept est celle qui commence par le numéro six, qui devrait précéder huit dans une liste correctement triée.
La sixième ligne du fichier (qui commence par « 8 Odell ») était la dernière traitée, nous voyons donc la sortie pour cela.
Vous pouvez utiliser l'option –check-order si vous voulez voir si join est satisfait de l'ordre de tri des fichiers – aucune fusion ne sera effectuée.
Pour ce faire, nous tapons ce qui suit :
join --check-order file-1.txt file-3.txt
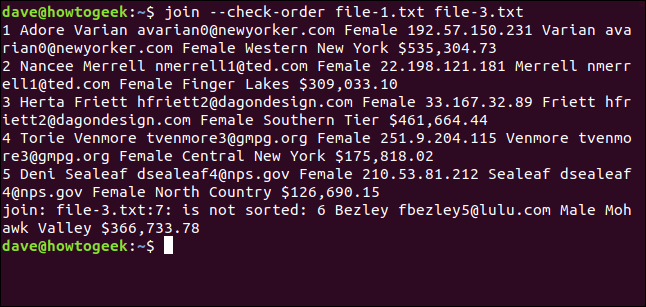
join vous indique à l'avance qu'il y aura un problème avec la ligne sept du fichier file-3.txt.
Fichiers avec lignes manquantes
Dans le fichier-4.txt, la dernière ligne a été supprimée, il n'y a donc pas de ligne huit. Voici le contenu :
1 Varian avarian0@newyorker.com Female Western New York $535,304.73
2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10
3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44
4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02
5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15
6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78
7 Standen ustanden6@geocities.jp Female Capital District $674,634.93
Nous tapons ce qui suit et, étonnamment, join ne se plaint pas et traite toutes les lignes qu'il peut :
join file-1.txt file-4.txt
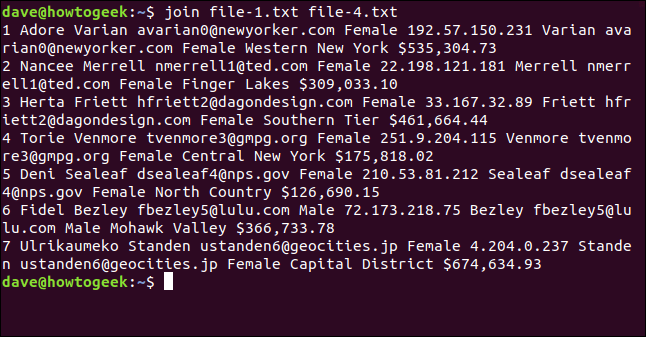
La sortie répertorie sept lignes fusionnées.
L'option -a (imprimer les lignes non appariées ou print unpairable) indique à join d'imprimer également les lignes qui ne peuvent pas être mises en correspondance.
Là, nous tapons la commande suivante pour indiquer à join d'imprimer les lignes du fichier un qui ne peuvent pas être mises en correspondance avec les lignes du fichier deux :
join -a 1 file-1.txt file-4.txt
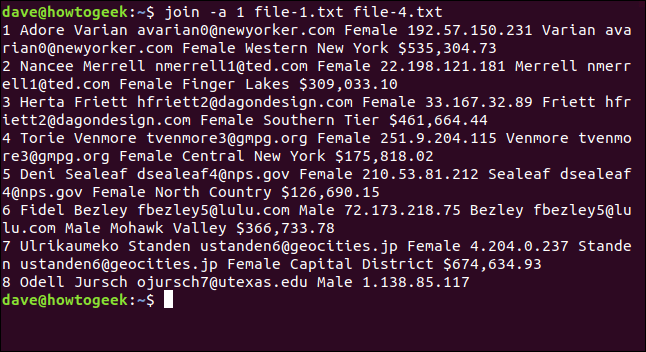
Sept lignes sont mises en correspondance et la ligne huit du fichier un est imprimée, sans correspondance. Il n'y a pas d'informations fusionnées, car le fichier-4.txt ne contenait pas de ligne huit à laquelle il pourrait être mis en correspondance. Cependant, il apparaît toujours au moins dans la sortie afin que vous sachiez qu'il n'a pas de correspondance dans le fichier-4.txt.
Nous tapons la commande -v (supprimer les lignes jointes) suivante pour révéler toutes les lignes qui ne correspondent pas :
join -v file-1.txt file-4.txt

Nous voyons que la ligne huit est la seule qui n'a pas de correspondance dans le fichier deux.
Faire correspondre d'autres champs
Associons deux nouveaux fichiers sur un champ qui n'est pas celui par défaut (champ un). Voici le contenu du fichier-7.txt :
avarian0@newyorker.com Female 192.57.150.231
dsealeaf4@nps.gov Female 210.53.81.212
fbezley5@lulu.com Male 72.173.218.75
hfriett2@dagondesign.com Female 33.167.32.89
nmerrell1@ted.com Female 22.198.121.181
ojursch7@utexas.edu Male 1.138.85.117
tvenmore3@gmpg.org Female 251.9.204.115
ustanden6@geocities.jp Female 4.204.0.237
Et voici le contenu du fichier-8.txt :
Female avarian0@newyorker.com Western New York $535,304.73
Female dsealeaf4@nps.gov North Country $126,690.15
Male fbezley5@lulu.com Mohawk Valley $366,733.78
Female hfriett2@dagondesign.com Southern Tier $461,664.44
Female nmerrell1@ted.com Finger Lakes $309,033.10
Male ojursch7@utexas.edu Hudson Valley $663,821.09
Female tvenmore3@gmpg.org Central New York $175,818.02
Female ustanden6@geocities.jp Capital District $674,634.93
L'adresse e-mail, qui est le champ un dans le premier fichier et le champ deux dans le second, est le seul champ raisonnable à utiliser pour se joindre.
Pour cela, nous pouvons utiliser les options -1 (fichier un champ) et -2 (fichier deux champ). Nous allons les suivre avec un nombre qui indique quel champ de chaque fichier doit être utilisé pour se joindre.
Nous tapons ce qui suit pour indiquer à join d'utiliser le premier champ du fichier un et le second du fichier deux :
join -1 1 -2 2 file-7.txt file-8.txt
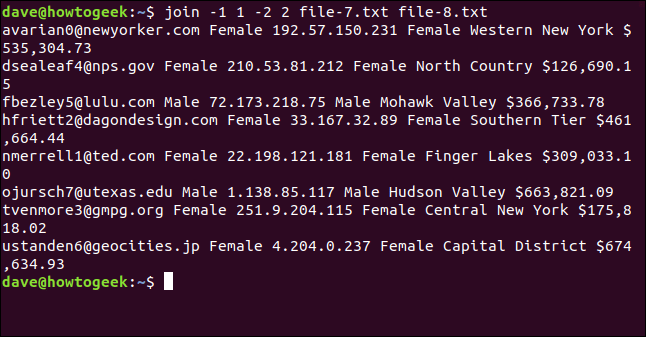
Les fichiers sont joints sur l'adresse e-mail, qui s'affiche comme le premier champ de chaque ligne dans la sortie.
Utiliser différents séparateurs de champs
Que faire si vous avez des fichiers dont les champs sont séparés par autre chose que des espaces ?
Les deux fichiers suivants sont séparés par des virgules. Le seul espace se trouve entre les noms de lieux de plusieurs mots :
cat file-5.txt
cat file-6.txt
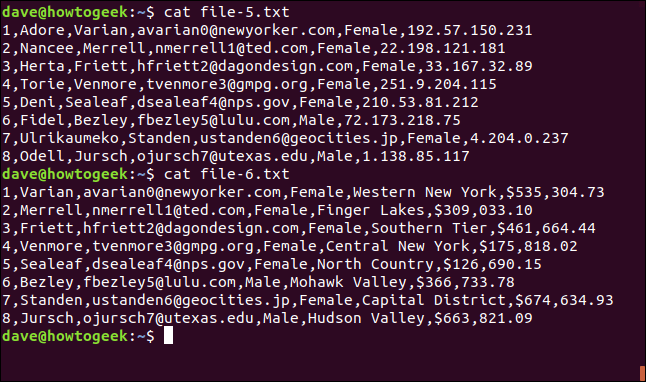
Nous pouvons utiliser le -t (caractère séparateur) pour indiquer à join quel caractère utiliser comme séparateur de champ. Dans cet exemple, c'est la virgule, alors nous tapons la commande suivante :
join -t, file-5.txt file-6.txt
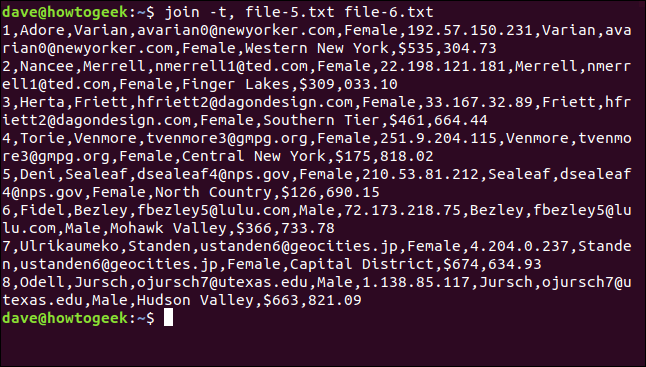
Toutes les lignes sont mises en correspondance et les espaces sont préservés dans les noms de lieux.
Ignorer la case des lettres
Un autre fichier, file-9.txt, est presque identique à file-8.txt. La seule différence est que certaines adresses e-mail ont une majuscule, comme indiqué ci-dessous :
Female avarian0@newyorker.com Western New York $535,304.73
Female dsealeaf4@nps.gov North Country $126,690.15
Male Fbezley5@lulu.com Mohawk Valley $366,733.78
Female hfriett2@dagondesign.com Southern Tier $461,664.44
Female nmerrell1@ted.com Finger Lakes $309,033.10
Male Ojursch7@utexas.edu Hudson Valley $663,821.09
Female tvenmore3@gmpg.org Central New York $175,818.02
Female ustanden6@geocities.jp Capital District $674,634.93
Lorsque nous avons rejoint file-7.txt et file-8.txt, cela a parfaitement fonctionné. Voyons ce qui se passe avec file-7.txt et file-9.txt.
Nous tapons la commande suivante :
join -1 1 -2 2 file-7.txt file-9.txt
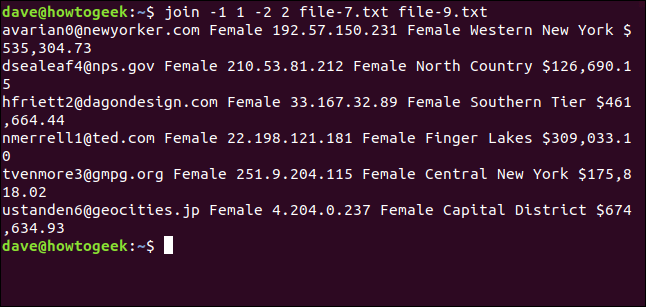
Nous n'avons fait correspondre que six lignes. Les différences dans les lettres majuscules et minuscules n’ont pas permis les deux autres adresses e-mail d'être jointes.
Cependant, nous pouvons utiliser l'option -i (ignorer la case) pour forcer join à ignorer ces différences et à faire correspondre les champs qui contiennent le même texte, quelle que soit la case.
Nous tapons la commande suivante :
join -1 1 -2 2 -i file-7.txt file-9.txt
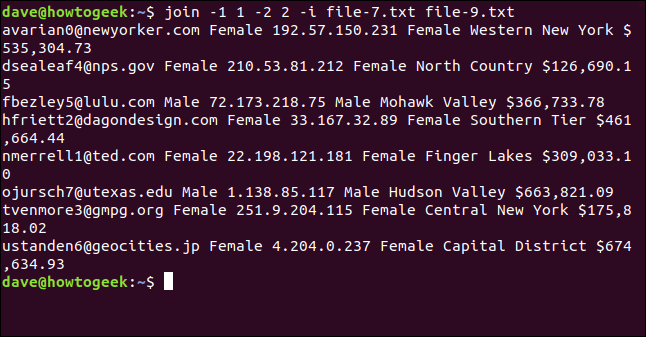
Toutes les huit lignes sont appariées et jointes avec succès.
Fusionner et apparier
Dans join, vous avez un allié puissant lorsque vous avez une difficulté avec une préparation de données. Vous devez peut-être analyser les données, ou essayer de les masser pour effectuer une importation vers un autre système.
Quelle que soit la situation, vous serez heureux d'avoir join !

Je m’intéresse également à la formation en ligne et à la transmission de compétences techniques. J’ai travaillé sur des contenus pédagogiques autour de l’hébergement Web, de la gestion de serveurs et plus récemment de l’automatisation par l’intelligence artificielle.
Mon approche repose sur l’expérimentation concrète, l’analyse technique et la recherche de solutions durables. Sur TopHebergeur, je partage des comparatifs et guides basés sur l’expérience terrain et l’étude approfondie des outils du marché.
- Cloudways Site Manager : gérer et migrer vos sites WordPress plus simplement - 29 juin 2026
- Cloudways ou Bluehost pour WordPress : lequel choisir ? - 25 juin 2026
- Comment installer OpenClaw sur un VPS (Guide complet avec Contabo) - 15 février 2026